我自己也创立了油管频道,所以对于油管的教程关注比较多,今天介绍这个教程是关于如何从YouTube Shorts获得免费流量以及如何解放劳动力,使用 python自动化该过程。
教程有些许门槛,涉及一些基础的编程知识,本文涉及很多的下载链接,如果确实没法消化或者不感兴趣,可直接划到最下方领取免费脚本。建议收藏,等到后期需要的时候再拿出来测试。
介绍的是思维以及运作的方法,你需要自己寻找不同的利基市场和货币化选项。
不应该简单地复制本电子书中提到的示例方法。此教程并非致富指南,而是一种经过充分研究的流量变现方法。
在本指南中分享的所有代码都经过测试,并在发布时可正常运行。考虑到YouTube算法可能会发生变化,因此请理解您可能需要调整您的频道策略。
洞察:对于垂直短视频,YouTube和Tiktok还有有一些区别,Youtube并不关心帐户的年龄,只要您可以验证与帐户关联的电话号码和电子邮件就能解锁额外的高级功能,例如在社区帖子和描述中添加链接。不过,YouTube和TikTok一样都是从原籍国推送内容。这意味着,如果您创建一个频道并上传来自爱尔兰的短视频,则超过 90%的视频观看者将来自爱尔兰,YouTube会尝试尽可能将其推送到本地。幸运的是,Youtube可以有办法克服这个问题,这个教程推荐的方法是专用 VPS。全自动短频道运行在具有2GB内存的共享 VPS 上。具有此类规格的虚拟服务器的价格可低至 5 美元/月。如果你不愿意在没赚钱的情况下进行任何投资,你可以先在你的电脑上运行。知道这个算法以及解决的方法就行了。
接来下进入正题:
获取YouTube shorts内容的方法数不胜数,但在本指南中,我将展示卡通和Reddit 故事的示例。这两个示例想法都可以获得大量的日常流量,但这些可能不是货币化的理想的利基。您可以简单地调整下面演示的方法来适应您自己的想法和利基。
栗子1:Short Reddit horror stories
栗子2:Random funny cartoon clips
步骤1:
您将需要Python来运行自动化。截至本指南发布,最稳定的版本将是 3.9.16(不是最新版本)
下载链接:https://www.python.org/downloads/
步骤2:
安装所需的库。为了让事情变得更简单,我们将安装一些 Python库来帮助我们完成自动化过程。要安装库,只需打开终端并输入 pip install library-name
为您的项目创建一个新文件夹,输入 cd 并将该文件夹拖放到终端窗口顶部。然后我们就可以开始安装库了。它应该看起来像这样:
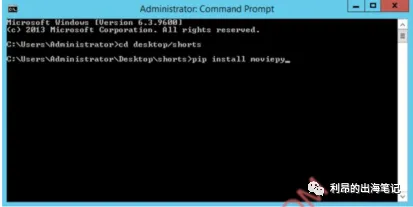
这是我们需要的所有库的列表:
-MoviePy https://pypi.org/project/moviepy/
-Requests https://pypi.org/project/requests/
-Naked https://pypi.org/project/Naked/
-NLTK https://pypi.org/project/nltk/
-TTS https://pypi.org/project/TTS/
-BS4 https://pypi.org/project/beautifulsoup4/
其他需求:
-eSpeak TTS module for Windows
https://github.com/espeak-ng/espeak-ng/releases/tag/1.51
-Some sort of text editor of your choice
-FFMPEG library for Windows
https://github.com/BtbN/FFmpeg-Builds/releases
-lmageMagic editor software
步骤3:
我们需要一些内容来使用,第一个示例将包括Reddit。没有多少人知道 Reddit 有这个功能。如果您转到任何 Reddit子版块并在 URL 栏中输入/random,您就会从该 Reddit 子版块中获得一个随机帖子。这意味着获取内容的系统已经就位,我们只需要“刮掉它”。我个人喜欢恐怖故事,所以让我们尝试使用 /r/shortscarystories 中的故事创建一些恐怖短片。
所以我们找到了我们想要的内容,但我们不想每次都自己复制粘贴。让我们编写一个简短的脚本来为我们完成这件事。在撰写本指南时,Reddit 的旧移动网站仍然处于活动状态,这非常方便抓取,因为它简单且加载速度快。我们可以通过输入 i 来访问它。在reddit.com前面。
该脚本的主要目标:
1.导航至https://i.reddit.com/r/shortscarvstories/random
2.找到正文的元素
3.从元素中提取故事文本
4. 将故事保存到文件
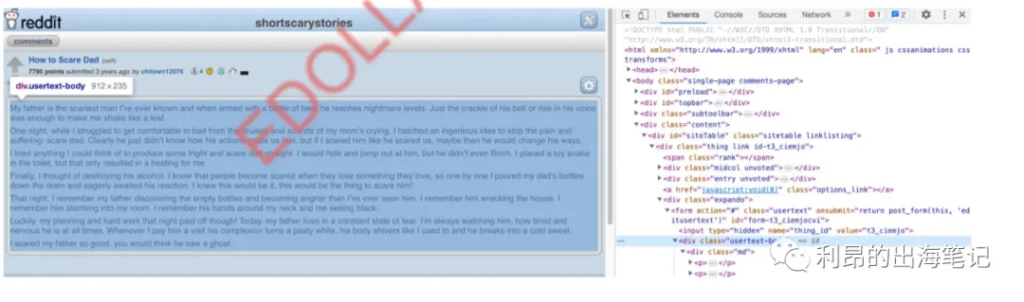
正如您所看到的,帖子的主体文本位于一些带有名为 usertext-body 的类的 div 标签之间,我们所要做的就是告诉我们的机器人导航到网页,找到具有相同类的元素,并获取文本。对于此任务,我们将使用 Requests库 来访问站点,并使用 BS4 来解释站点的HTML。就像任何流行网站一样,Reddit不喜欢机器人抓取他们的页面,但幸运的是,只要你不这样做,他们对此并没有那么严格。
为避免造成太多麻烦,让我们使用随机用户代理以防万一。如果您想抓取更多数据,可以使用他们的 API 来实现,但在本教程中,我们将保持简单。
它应该以 .py 文件扩展名保存,并且可以通过打开终端并输入py yourscript.py 进行测试脚本应该在同一目录中创建一个新的 .txt 文件。
步骤4:
通过上面的操作,我们有了内容,让我们制作视频吧!
您可以手动完成,但这并不有趣,所以让我们编写另一个python 脚本,将其转换为视频。
该视频将包括:
– 库存背景素材
– 叠加故事字幕
– 文字转语音
– 旁白背景音乐
该脚本的目标是将库存背景素材裁剪为 9:16 的宽高比,使用 TTS 将 Reddit 故事转换为音频,将其切成适合屏幕的单独文本行,使用 TTS 将这些行转换为音频并叠加,让它带有一些背景氛围。
在此代码的开头,我们定义必要的库并下载 NLTK 模块,该模块有助于将我们的脚本分成更小的句子,以使字幕适合屏幕。然后我们选择所需的 TTS 语音。第一次尝试此代码时,TTS 库将下载所选的语音。除了英语之外,还有相当多的语言,只需更改型号名称即可选择您想要的声音。
注意:
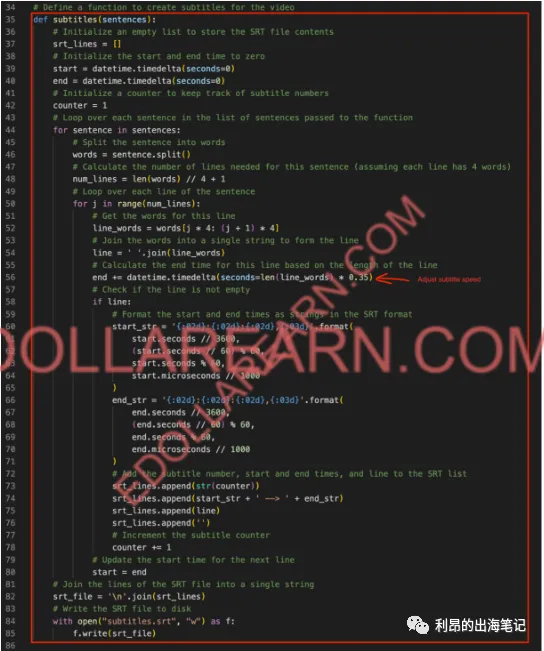
我标记了更改字幕速度的数字(更少 = 更快),但是要更改每 1 个字幕行的最大字数,您需要将所有 4 更改为所需的数字。当前设置为每个字幕行最多 4 个单词,因为使用当前字体很难在垂直视频中容纳更多单词。
以上自动化的方法也适用与其他平台,例如tiktok。
完整且可复制的脚本如下:
从 Reddit 上抓取内容
->https://pastebin.com/ZYU3KRZn
从故事生成视频
->https://pastebin.com/gXHZ98Hz
从电视剧集剪辑
->https://pastebin.com/U5RpYK70
Reddit 到视频
->https://pastebin.com/TdyF60wF
卡通剪辑
->https://pastebin.com/1PEYc2tW
视频上传
->https://pastebin.com/USsm1pKC
对于脚本感兴趣的同学可以再深入研究,但是基于YouTube和Tiktok算法随时可能会发生变化,因此需要随时调整策略。
教程整理不易,不知道是否能对你形成帮助,或许也能开阔一点思路,应用到其他的领域或者实践当中,那么我也会觉得这件事很酷。
最后也希望各位点个“在看”和收藏,感谢大家的支持,后续我们会更新一些更容易实操以及进阶的教程,感谢关注!