
为了给读者提供更详细更全的赛道选择,我准备开始拆解几个小红书的热门赛道,短期可以快速变现的那种。
首先我们上篇文章讲过,电商最重要的就是选品,把正确的产品卖给正确的人,目前小红书的电商模式非常不成熟,整体利润也很有限,加上电商本身的环节非常多,一个人难以做大做强。
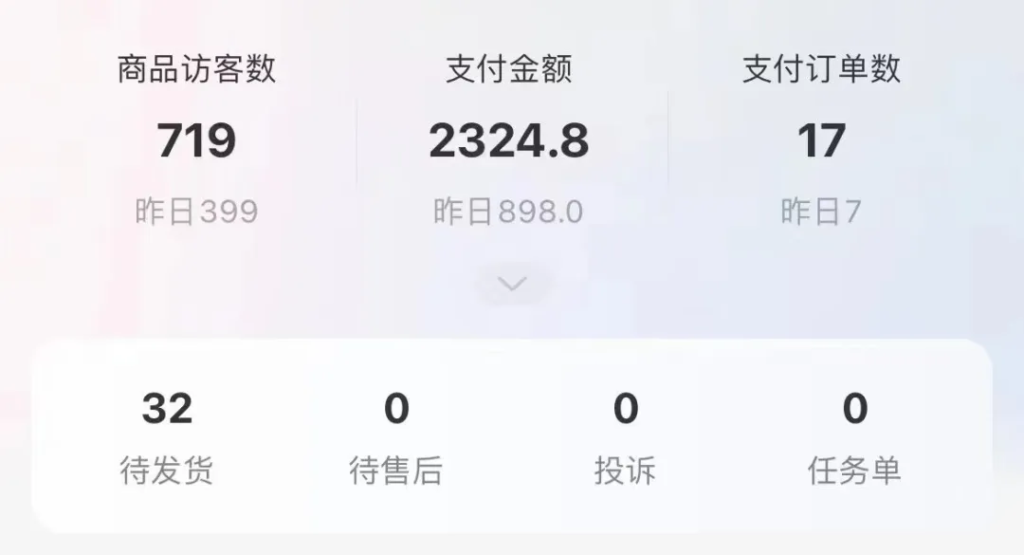
现在抖音上一大堆教你开店卖货,文案都是一模一样,颇有之前独立站刚火起来的那种感觉。有一张图可以说明目前电商的整体现状:
既然如此,这个赛道对于一般个人而言,除非有特殊的产品资源或者运营资源,否则就不要去卷了,特别是无货源这种,单就售后这一块就有你受的。
那么作为个体应该选择什么赛道?上篇文章已经做了说明。《都在叫你做小红书,唯独却不说这个》
我们今天就来讲讲其中一个:AI+定制图片这里的图片可以是壁纸、贴纸、头像等,你可以细分人群,做儿童、亲子、职场,当然还可以细分风格:动漫、科技、童话…根据你的兴趣你可以随意排列组合,例如:儿童+童话,科技+职场,动漫+职场…小红书的受众人群对于此类新鲜事物的接受程度,可以说是目前全媒体里面最高的。
我们看一下效果图片:

变现模式:定制化的图片服务,一张图客单价在50元左右,可以上平台,也可以引流到私域变现。

每天做几单,收益还是很不错的,主要客户一般不会只要一张,而是做一个系列,所以客单价还是很可观:
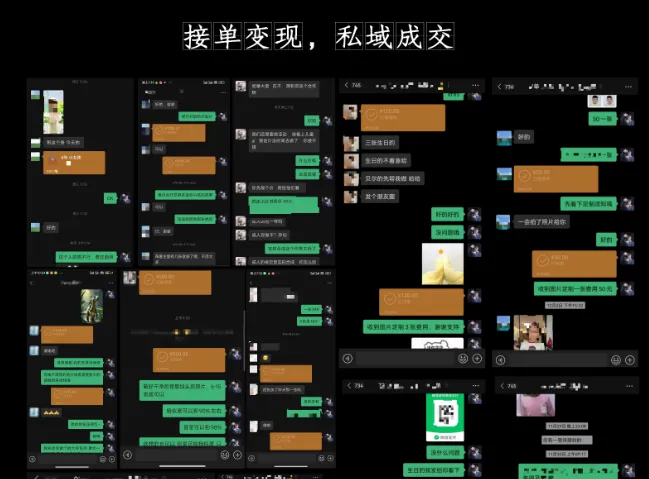
下面我们介绍具体的操作步骤:工具:stable diffusion 和 midjourney使用门槛:
- 需要科学上网
- midjourney 需要付费
- 电脑配置要求不能太低
midjourney的官网:https://www.midjourney.com/app/stable diffusion 是一个免费的开源工具包,可以在本地安装,直接使用本地计算资源就可以进行绘画创作,同时stable diffusion提供了很多可以扩展的插件,可以根据场景需要,进行自定义功能扩展。
stable diffusion安装
stable diffusion的安装直接参考官网提供的安装指南即可:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
这里有各种芯片组使用的安装方式,我的电脑是 apple芯片,安装方式使用的是:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon
安装过程主要分为如下5步,如下图:
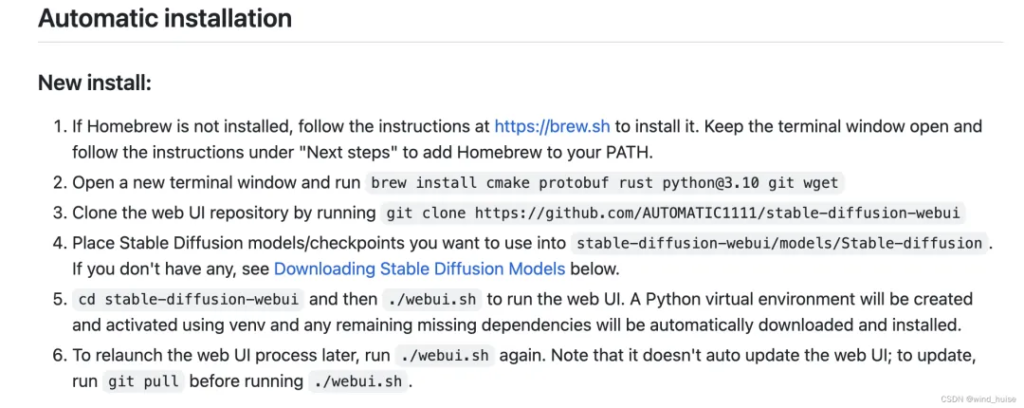
注意:这里使用了Home Brew完成对需要依赖的安装,如果不会操作的话,也可以使用国内镜像安装,操作方式可以参考:https://zhuanlan.zhihu.com/p/111014448/
按照上述步骤,经过10-20分钟后,可以完成安装。
安装完成后,在 stable-diffusion-webui 目录下执行./web-ui.sh,第一次执行会比较慢,会下载一些基础模型和依赖,大概等待5-10分钟后,在控制台会看到如下图输出,说明启动成功。

此时在浏览器访问地址:http://localhost:7860 即可。此时你会看到如下图所示的页面:

在上图中,一种有7个重点区域。
1.模型选择区模型对于画图至关重要,它直接决定了你要出图的风格,对于初学者直接使用其他人提供的模型就行,模型的下载后面会详细说。
2.功能区stable diffusion支持多种绘图能力:
- 文生图:根据提示词描述完成图片生成
- 图生图:使用提供的图片作为参考,完成新图片的生成
- 高清化:将已有图片进行高清化处理
- 图片信息:如果一个图片是stable diffusion生成的,那么使用图片信息功能,可以输出生成这张图片使用的模型、提示词等信息
- 模型合并:是一种高阶使用方式,可以将多个模型合并生成一个全新的模型
- 训练:使用者可以根据自己的一些图片数据进行训练,生成一个全新的模型
- setting:是对stable diffusion进行配置的控制面板,具体控制项,读者可以自行查看
- 扩展:可以实现对stable diffusion进行插件功能扩展,来实现对stable diffusion进行功能增强,扩展功能下面会进行具体演示
3.正向提示词正向提示词是你与模型对话的输出框,告诉模型你想要什么,告诉模型你要绘画的内容,如人物特征,形象,背景,图片质量等。
4.反向提示词和正向提示词作用相反,就是告诉模型,你不想要什么,通常模型在输出的图形的上会有一些瑕疵,如怪异的手指,眼睛等一些细节,你可以在这里输入这些你不想要的内容。
5.图片输出参数区这些参数主要是控制输出图片的一些控制参数。
- 宽度、高度:这两个参数直接控制输出图片的尺寸大小,当如输出图片尺寸越大,生成图片耗时越长
- 采样步数(Sampling steps):决定了模型输出图片迭代的次数,迭代次数越多,耗时越长,但是效果却不是越好的,这个迭代次数,通常20-30直接,当然也取决于具体的模型,可以在生成图片的时候,可根据具体情况调整
- 生成次数和每次数量:决定了一次生成任务可以生成多个张图片,生成图片越多,耗时也就越长。
6.图片生成
点击生成按钮,模型就开始根据你设置的参数来执行图片生成了动作了,可以根据进度条查看图片生成的进度。
模型下载
上面介绍模型选择区的时候说过,模型对于stable diffusion来说至关重要,他决定了绘画的风格,比如你想要画一副二次元风格的图片,那么就尽量选择一个二次元画风的模型,模型的选择要比你输入多少提示词都要好使。对于新手小白来说,可以使用别人训练好的模型直接使用,模型的选择和下载可以到下面这个两个网站:
- https://huggingface.co/models
- https://civitai.com
模型主要分为两种:大模型(checkpoint)和微调模型(lora)。以Lora大模型为例,我们进行一次操作。
1.进入C站后,可以浏览自己需要的大模型,也可以有目标的搜索自己需要的模型
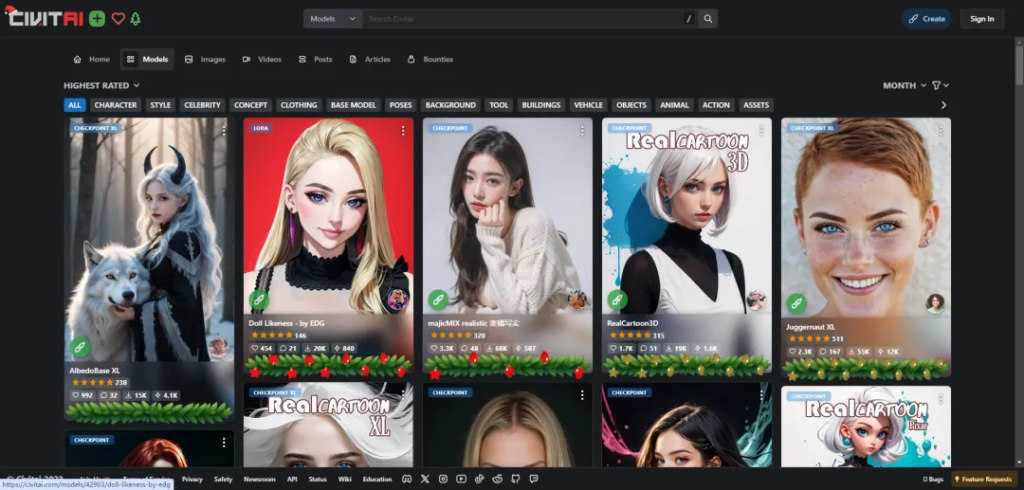
2.选中自己需要的模型,点击下载按钮,就会进行模型的下载,通常大模型会比较大,lora模型不是太大。

3.点击演示图片右下方的 “i”,可以查看演示图片的配置信息:正方向提示词,使用的模型等,使用演示图片的配置信息进行模型的验证。
4.模型下载完毕后,需要将模型文件放到/stable diffusion/stable-diffusion-webui/models/Lora目录下,重启 stable diffusion,在模型选择区就可以看到自己需要的模型了。
在stabel diffusion的模型中,Lora是一种微调模型,但是对于生成图片的影响也比较明显,会影响生成图片的一些细节和图片的背景。
lora模型如何使用呢?
lora模型会作为一个正向提示词,出现在正向提示词输入框中,使用形式如下:
<lora:LORA_CNCG_arts:1>
LORA_CNCG_arts:表示lora模型名称
表示模型权重,在一个正向提示词输入框中可以使用多个lora模型,但是多个模型的权重之和不能超过1。
下载下来的模型都是一个文件,文件名称描述性也不高,有没有一个缩略图,可以直观的看出这个模型画出的图大概长什么样子?
其实是可以的,点击在如下图所示的按钮,可以查看你的stable diffusion已经安装了哪些模型。
在下载模型的时候,在模型所在的文件夹中,放入一张和模型名称相同的图片,那么这个图片成了模型的预览图了,而且,当你选中某个模型时,stable diffusion就会直接使用这个模型。效果如下:

到这里,你就完成完成 stable diffusion的入门了,可以使用stable diffusion完成基本的绘图操作了,不过对于不是设计专业出身的朋友来说,想要完整的描述出自己想要的那副画面来说还是比较难的,譬如如何与stable diffusion进行高效的沟通,再直接一点就是如何写提示词。
以上仅仅是一些基础的操作,如果想要得到我们之前说的那种效果,还需要一些服装的更换技巧以及如何做手部以及脸部的修复等等,当然还会有一些图生图+涂鸦重绘合成技巧。
如果对这方面很感兴趣的盆友,可以私信我,为了避免广告嫌疑,文章就不放联系方式了,当然这个课程也是要收费的,对于确实感兴趣要往这个方向发展的朋友再来联系。

Pingback: 全网最简单的AI换脸教程(效果超乎你想象) - Income Leone